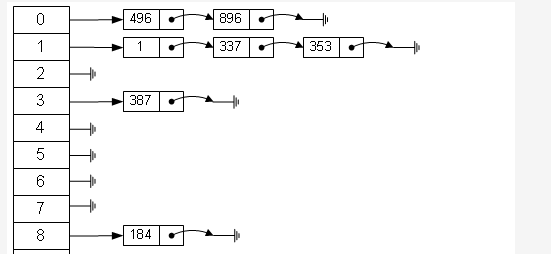
从HashMap并发的死循环可以知道,Hashmap是没办法在多线程的情况下使用的,为了解决这个问题,在Java4之前用的是hashtable,只是现在不推荐的。在Java5之后就比较推荐使用java.util.concurrent.ConcurrentHashMap,这个在多线程的情况下,也能有很好的性能。从这里引入了Java里面一类很重要的概念—并发。先解决完上一个问题。高并发下ConcurrentHashMap的结构。
并发的一些初步了解–synchronized和volatile
在多线程的并发的情况下有安全的访问变量,为了解决这个问题引入一个机制—锁机制。让多线程不能同时访问一个共享变量。在并发过程中有需要简单的了解两个东西的含义。
Java中的synchronized的简单分析
synchronized的用法要弄清晰一个问题:synchronized锁住的是代码还是对象?
首先是一个被synchronized修饰的代码块