HashMap从设计上来说就不适合在并发的情况的下使用,因为HashMap每次在put()时,总会检查一遍对应桶的容量,如果桶满了,或者超过了设定的值,就会reserve()来进行扩容,然后通过get()来取出相应的值。这个过程在单线程下是没什么问题的,但是如果在并发的条件下,多个线程同时reserve桶,然后有线程这个时候执行get()就有可能产生死循环,造成CPU的100%占用,具体等会看源码。在Java里面有一个很老的hashtable就是加了锁的HashMap。现在Java中多线程里一般使用ConcurrentHashMap,至于为什么。会在下一篇博文里分析。
HashMap的rehash源代码
put()方法的Java8源码分析看我的Java里的hashMap和golang里的map,在Java8中优化了扩容的hash算法,更加高效。在这分析死循环用的是Java7的源码。更加清晰点。
1 | void resize(int newCapacity) { |
在单线程中的执行流程其实是很直观的:先对要插入的元素进行哈希,在数组中找到相应的位置,如果发生冲突就变成链表存储,在看桶有没有满。有就进resize()扩容操作。但是在多线程的时候由于扩容操作产生环形链,会造成get()方法命中时—-Infinite Loop,然后CPU爆炸。
举例分析(网上一个很经典的例子–引用自酷壳)
假设我们的hash算法是简单的key mod一下表的大小(即数组的长度),现在有两个线程:一个蓝色标注,一个红色标注。
关键代码在transfer()中把旧的table的Entry转移到新的table中的时候
1 | do { |
两个线程在蓝色线程执行完后的情况。这个时候红色线程中的e指向了key(3),而next指向了key(7),但是在蓝色线程中链表已经扩容完成,并且链表的顺序被反转 ,这个时候就有了环链的征兆了。e的下一个节点本来是next,经过蓝色线程扩容后变成了next下一个节点是e。就有很大的几率产生环形链。
接着看,这个时候红色线程得到了执行的机会.被调度回来进行执行,
先是执行newTalbe[i] = e;,然后是e = next,导致了e指向了key(7),而下一次循环的next = e.next导致了next指向了key(3)。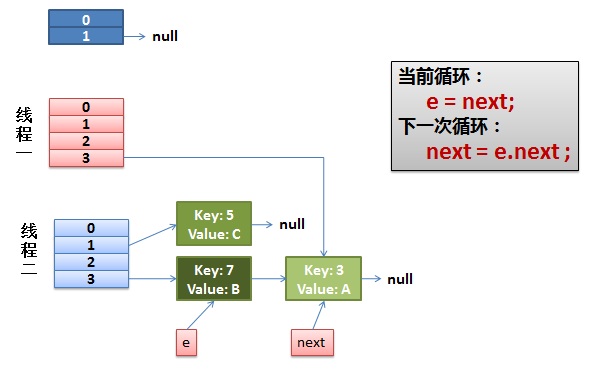
然后红色线程接着工作,把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。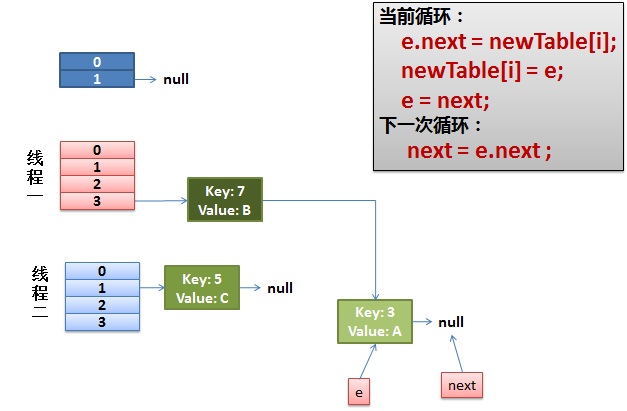
然后重点来了:e.next = newTable[i]导致key(3).next指向了key(7)。但是此时的key(7).next 已经指向了key(3),环形链表就这样出现了。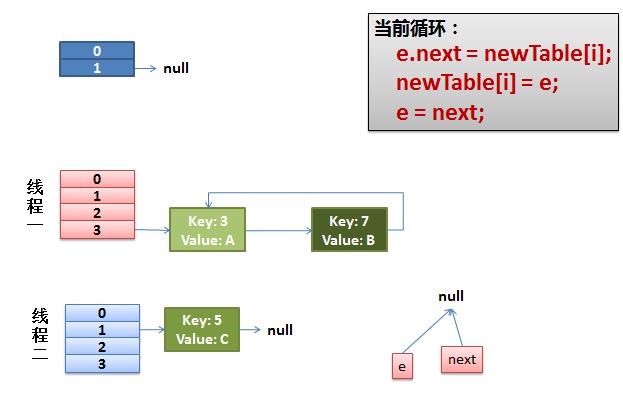
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。